Posts in Category: representation
representational effects (e.g., on arithmetic or logical thinking)


Paper: Decade effects in mental addition
| The most important part of the Analytical Engine was undoubtedly the mechanical method of carrying the tens. (…) The difficulty did not consist so much in the more or less complexity of the contrivance as in the reduction of the time required to effect the carriage. (…) nothing but teaching the Engine to foresee and then to act upon that foresight could ever lead me to the object I desired… |
| Charles S. Babbage (1864), Passages from the Life of a Philosopher, p. 114 |
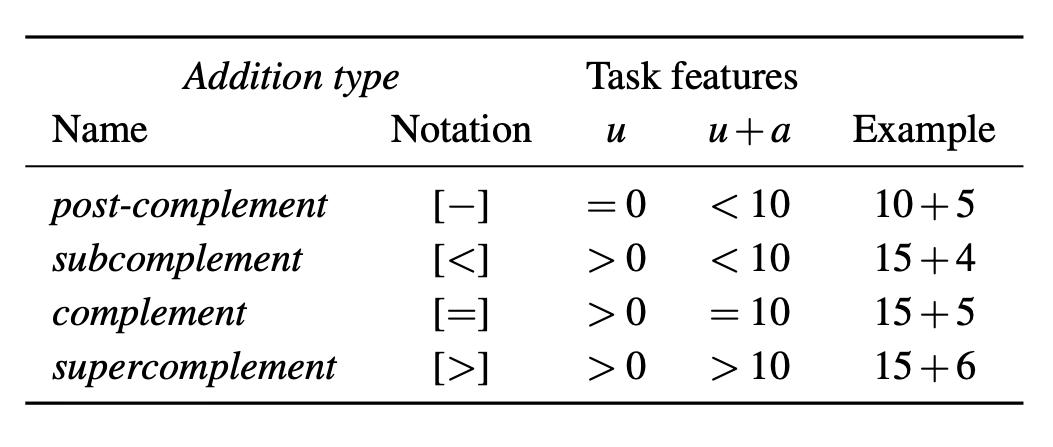
Classification of addition types for adding a single-digit addend a (with a∈{1…9}) to an augend Au (u denoting the augend’s unit). (See Table 1 for details.)
Hansjörg Neth, Stephen J. Payne
Decade effects in mental addition
We examine representational effects of Western numerals on mental arithmetic. An analysis of mental addition tasks using a base-10 place-value notation yields a taxonomy of addition types that is anchored in the notion of complements (i.e. additions with round sums). Two experimental studies use a paradigm of serial addition that presents lists of numbers to adult participants, who mentally represent all intermediate steps. In study 1, participants add sequences of single-digit addends in a self-paced fashion. Study 2 extends this paradigm by simultaneously presenting two addends, thus allowing for a modicum of strategic choice. Both studies vary the number of complements within the lists and measure addition accuracy and latency. Beyond decade and carry effects, our results show that lists containing or enabling complements are easier to add. Addition latencies jointly depend on addition type and problem size. When adders have some discretion about the order of choosing addends, they adaptively exploit the difficulty of addition types by tailoring their sequences to decade boundaries. One motivation for seeking complements lies in enabling subsequent post-complements. Reflecting on the dynamic interplay between numeric representations, strategic choices and cognitive adaptations, we discuss implications for psychological explanations, technology and design.
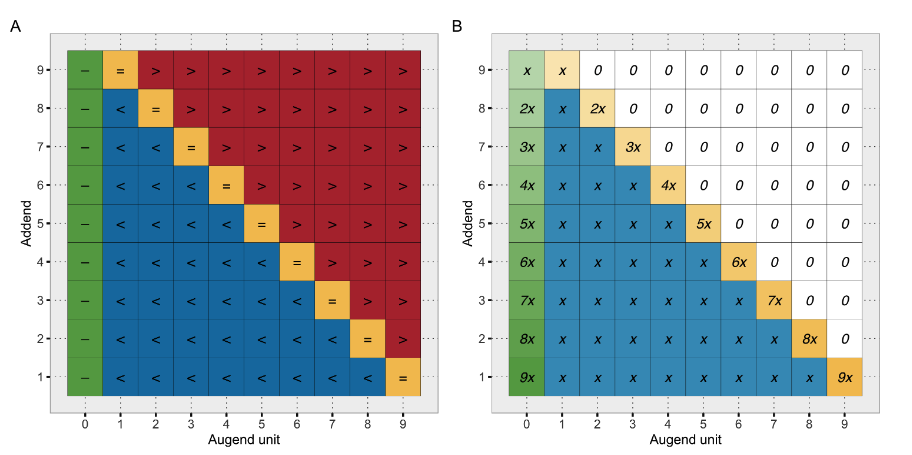
Four different addition types (A) and their hypothetical frequency (B, assuming uniform distribution of addends 1–9 and full decomposition of super-complements). (See Figure 4 in Appendix A1 for details.)
This article is part of the theme issue A solid base for scaling up: the structure of numeration systems.
Keywords: mental arithmetic, addition strategies, base notation, representational effects.
Reference: Neth, H., & Payne, S. J. (2025). Decade effects in mental addition. Philosophical Transactions of the Royal Society B, 380, 20240220. https://doi.org/10.1098/rstb.2024.0220
Related: Addition as interactive problem solving | Thinking by doing? | Immediate interactive behavior (IIB) | Arabic vs. Roman arithmetic | Taxonomy of actions | The cognitive basis of arithmetic | Interactive coin addition | The functional task environment
Resources: open access article | PDF download | Google Scholar


Chapter: How can decision models decide to not decide? Modeling suspension in fast-and-frugal trees (FFTs)
Hansjörg Neth, Jelena Meyer
How can decision models decide to not decide?
Modeling suspension in fast-and-frugal trees (FFTs)
Abstract
The phenomena of indecision and suspension loom large in both philosophy and psychology. Whereas psychology discusses related phenomena in practical tasks and mostly pathological terms, philosophy strives for conceptual clarification and emphasizes the ubiquity and variety of suspension.
In this chapter, we use fast-and-frugal trees (FFTs) as a drosophila model for developing a positive account of suspension in decision-making. Being designed for handling binary classification tasks, FFTs seem particularly ill-suited for accommodating a third stance. But by replacing one decision outcome by a do not know category or adding it as a third option, we can adapt and extend the FFT framework to explore the causes and consequences of suspension.
Considering the distributions of decision outcomes and contrasting the performance of alternative models in terms of cost-benefit trade-offs illustrates the power of this methodology. Overall, a model-based approach provides surprising insights into the functions and mechanisms of suspension and serves as a productive tool for thinking.
Keywords
-
fast-and-frugal trees (FFTs), judgment and decision making (JDM), heuristics, binary classification, cost-benefit trade-offs, indecision, computer modeling, philosophy, machine learning, suspension
Reference
- Neth, H., & Meyer, J. (2025). How can decision models decide to not decide? Modeling suspension in fast-and-frugal trees (FFTs). In V. Wagner & A. Zinke (Eds.), Suspension in epistemology and beyond (pp. 286–303). New York, NY: Routledge.
doi 10.4324/9781003474302-20

Related: FFTrees: An R toolbox to create, visualize, and evaluate FFTs
Resources: 10.4324/9781003474302-20 | Download PDF | Google Scholar
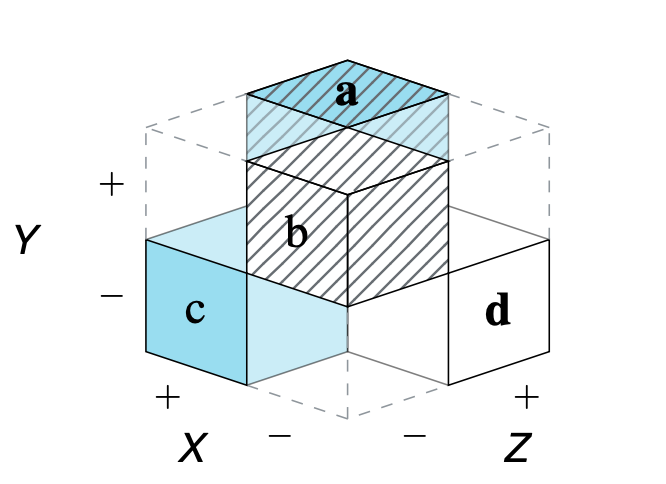
Paper: Perspectives on the 2×2 Matrix
Hansjörg Neth, Nico Gradwohl, Dirk Streeb, Daniel A. Keim, Wolfgang Gaissmaier
Perspectives on the 2×2 matrix: Solving semantically distinct problems based on a shared structure of binary contingencies
Abstract
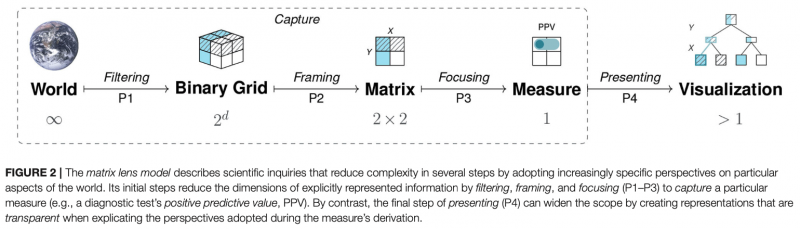
Cognition is both empowered and limited by representations. The matrix lens model explicates tasks that are based on frequency counts, conditional probabilities, and binary contingencies in a general fashion. Based on a structural analysis of such perspective on representational accounts of cognition that recognizes representational isomorphs as opportunities, rather than as problems.
The shared structural construct of a 2×2 matrix supports a set of generic tasks and semantic mappings that provide a tasks, the model links several problems and semantic domains and provides a new unifying framework for understanding problems and defining scientific measures. Our model’s key explanatory mechanism is the adoption of particular perspectives on a 2×2 matrix that categorizes the frequency counts of cases by some condition, treatment, risk, or outcome factor. By the selective steps of filtering, framing, and focusing on specific aspects, the measures used in various semantic domains negotiate distinct trade-offs between abstraction and specialization. As a consequence, the transparent communication of such measures must explicate the perspectives encapsulated in their derivation.
To demonstrate the explanatory scope of our model, we use it to clarify theoretical debates on biases and facilitation effects in Bayesian reasoning and to integrate the scientific measures from various semantic domains within a unifying framework. A better understanding of problem structures, representational transparency, and the role of perspectives in the scientific process yields both theoretical insights and practical applications.
Why read this paper?
This paper is quite long and covers a wide array of concepts and topics. So what can you expect to gain from reading it?
riskyr: A toolbox for rendering risk literacy more transparent
so as to make the solution transparent.
Hansjörg Neth, Felix Gaisbauer, Nico Gradwohl, Wolfgang Gaissmaier
riskyr: A toolbox for rendering risk literacy more transparent
Abstract: Risk-related information — like the prevalence of conditions and the sensitivity and specificity of diagnostic tests or treatment decisions — can be expressed in terms of probabilities or frequencies. By providing a toolbox of methods and metrics, the R package riskyr computes, translates, and displays risk-related information in a variety of ways. Offering multiple complementary perspectives on the interplay between key parameters renders teaching and training of risk literacy more transparent.