Posts in Category: computer science
computer science and informatics, information retrieval


Chapter: How can decision models decide to not decide? Modeling suspension in fast-and-frugal trees (FFTs)
Hansjörg Neth, Jelena Meyer
How can decision models decide to not decide?
Modeling suspension in fast-and-frugal trees (FFTs)
Abstract
The phenomena of indecision and suspension loom large in both philosophy and psychology. Whereas psychology discusses related phenomena in practical tasks and mostly pathological terms, philosophy strives for conceptual clarification and emphasizes the ubiquity and variety of suspension.
In this chapter, we use fast-and-frugal trees (FFTs) as a drosophila model for developing a positive account of suspension in decision-making. Being designed for handling binary classification tasks, FFTs seem particularly ill-suited for accommodating a third stance. But by replacing one decision outcome by a do not know category or adding it as a third option, we can adapt and extend the FFT framework to explore the causes and consequences of suspension.
Considering the distributions of decision outcomes and contrasting the performance of alternative models in terms of cost-benefit trade-offs illustrates the power of this methodology. Overall, a model-based approach provides surprising insights into the functions and mechanisms of suspension and serves as a productive tool for thinking.
Keywords
-
fast-and-frugal trees (FFTs), judgment and decision making (JDM), heuristics, binary classification, cost-benefit trade-offs, indecision, computer modeling, philosophy, machine learning, suspension
Reference
- Neth, H., & Meyer, J. (2025). How can decision models decide to not decide? Modeling suspension in fast-and-frugal trees (FFTs). In V. Wagner & A. Zinke (Eds.), Suspension in epistemology and beyond (pp. 286–303). New York, NY: Routledge.
doi 10.4324/9781003474302-20

Related: FFTrees: An R toolbox to create, visualize, and evaluate FFTs
Resources: 10.4324/9781003474302-20 | Download PDF | Google Scholar
riskyr: A toolbox for rendering risk literacy more transparent
so as to make the solution transparent.
Hansjörg Neth, Felix Gaisbauer, Nico Gradwohl, Wolfgang Gaissmaier
riskyr: A toolbox for rendering risk literacy more transparent
Abstract: Risk-related information — like the prevalence of conditions and the sensitivity and specificity of diagnostic tests or treatment decisions — can be expressed in terms of probabilities or frequencies. By providing a toolbox of methods and metrics, the R package riskyr computes, translates, and displays risk-related information in a variety of ways. Offering multiple complementary perspectives on the interplay between key parameters renders teaching and training of risk literacy more transparent.


Paper: FFTrees: An R toolbox to create, visualize, and evaluate FFTs
is nevertheless totally incomprehensible to a human expert, can it
be described as knowledge? Under the common-sense definition of this term
as material that might be assimilated and used by human beings, it is not…
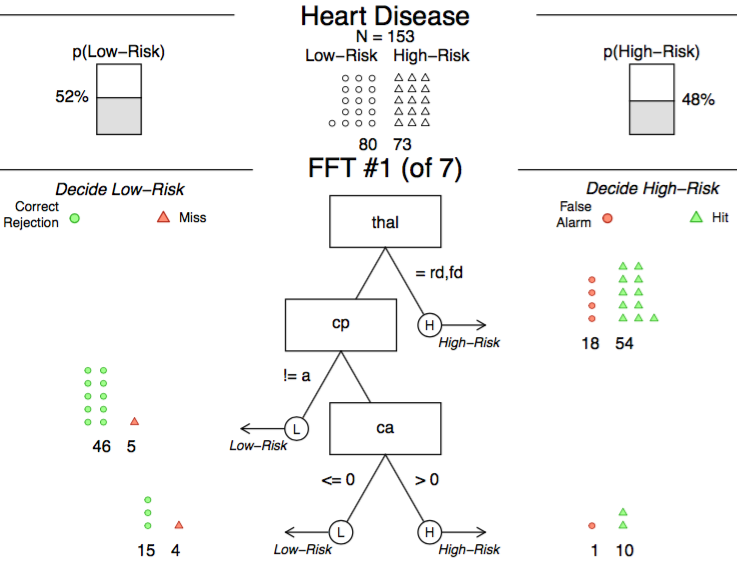
An example of an FFT predicting the risk of having heart disease.
Nathaniel Phillips, Hansjörg Neth, Jan Woike, Wolfgang Gaissmaier
FFTrees: A toolbox to create, visualize, and evaluate fast-and-frugal decision trees
Abstract: Fast-and-frugal trees (FFTs) are simple algorithms that facilitate efficient and accurate decisions based on limited information. But despite their successful use in many applied domains, there is no widely available toolbox that allows anyone to easily create, visualize, and evaluate FFTs. We fill this gap by introducing the R package FFTrees.


Paper: Ranking LOD data with a cognitive heuristic
Arjon Buikstra, Hansjörg Neth, Lael J. Schooler, Annette ten Teije, Frank van Harmelen
Ranking query results from Linked Open Data using a simple cognitive heuristic
Abstract: We address the problem how to select the correct answers to a query from among the partially incorrect answer sets that result from querying the Web of Data.